在当前数据驱动的时代,知识图谱作为组织和理解海量信息的关键技术,正从理论概念加速走向产业应用。对于提供基础软件技术服务的企业而言,成功推动知识图谱项目落地,不仅需要先进的技术栈,更需要一套清晰的原则指导与经过验证的最佳实践。本文旨在深度剖析这一过程中的基本原则与关键行动。
一、知识图谱落地的基本原则
- 业务价值驱动原则:一切技术落地必须始于明确的业务需求。知识图谱项目应聚焦于解决具体的业务痛点,如提升搜索精准度、实现智能推荐、优化风控模型或辅助复杂决策。避免为“图谱”而图谱,确保每一步投入都能产生可衡量的业务回报。
- 迭代演进与敏捷构建原则:知识图谱的建设并非一蹴而就。应采用“最小可行图谱”(MVP)的思路,从核心实体和关键关系入手,快速构建原型并验证价值,随后再基于反馈持续扩展和深化。这与基础软件技术服务中倡导的敏捷交付理念一脉相承。
- 数据质量与治理先行原则:“垃圾进,垃圾出”。在构建图谱前,必须对数据源进行严格评估与治理,包括数据的准确性、一致性、时效性和完整性。建立持续的数据质量监控和知识更新机制,是图谱保持生命力的基础。
- 技术与领域知识深度融合原则:成功的知识图谱是领域专家(懂业务)与技术专家(懂图谱)紧密协作的结晶。领域知识是图谱的灵魂,用于定义本体、规则与逻辑;技术能力是骨架,负责实现高效存储、计算与推理。两者缺一不可。
二、基础软件技术服务视角下的最佳实践
- 分层架构设计与技术选型:
- 基础层:根据数据规模(图规模、并发量)和查询模式,审慎选择图数据库(如Neo4j、Nebula Graph、TigerGraph)或基于关系数据库的扩展方案。考虑与现有数据湖/仓的集成能力。
- 构建层:构建自动化的知识获取与融合流水线。综合利用NLP技术(实体识别、关系抽取)、规则引擎、数据映射工具以及人工众包平台,实现从多源、异构数据到结构化知识的高效转换。
- 服务与应用层:提供标准化的图谱查询接口(如Gremlin、Cypher、GraphQL)和基于图谱的微服务(如智能问答、路径分析、社区发现API),方便上层业务系统快速集成和调用。
- 构建高效的“人机协同”知识流水线:
- 纯自动化的信息抽取往往精度有限。最佳实践是设计“机器抽取、人工校验、反馈优化”的闭环流程。利用主动学习等技术,优先将机器不确定的样本提交给领域专家标注,从而高效提升模型性能与知识质量。
- 实施全生命周期的运维与监控:
- 将知识图谱视为持续运营的产品而非一次性项目。监控核心指标:图谱构建的吞吐量与准确率、查询响应延迟、系统资源消耗、业务应用的使用情况与效果度量(如推荐点击率、搜索满意度)。建立知识的新增、修正、淘汰流程。
- 重视安全、合规与权限管控:
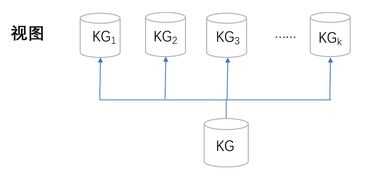
- 知识图谱集中了企业核心知识资产,必须实施严格的数据安全与访问控制。这包括数据脱敏、基于属性的访问控制(ABAC)确保“不同人看到不同的图”,以及满足GDPR等数据合规要求,实现知识的可追溯与可审计。
###
对于基础软件技术服务商而言,推动知识图谱成功落地,其角色不仅是技术工具的提供者,更是方法论的引导者和价值实现的赋能者。牢牢把握“业务驱动、迭代构建、数据为本、人机结合”的核心原则,并扎实落地从架构设计到持续运营的全套实践,方能将知识图谱这一强大的认知智能基础设施,转化为客户切实的竞争力与创新引擎,最终在数据智能的浪潮中赢得先机。